voidDBImpl::MaybeScheduleCompaction(){ mutex_.AssertHeld(); if (background_compaction_scheduled_) { // Already scheduled } elseif (shutting_down_.load(std::memory_order_acquire)) { // DB is being deleted; no more background compactions } elseif (!bg_error_.ok()) { // Already got an error; no more changes } elseif (imm_ == nullptr && manual_compaction_ == nullptr && !versions_->NeedsCompaction()) { // No work to be done } else { background_compaction_scheduled_ = true; env_->Schedule(&DBImpl::BGWork, this); } }
voidDBImpl::MaybeScheduleCompaction(){ mutex_.AssertHeld(); if (background_compaction_scheduled_) { // Already scheduled } elseif (shutting_down_.load(std::memory_order_acquire)) { // DB is being deleted; no more background compactions } elseif (!bg_error_.ok()) { // Already got an error; no more changes } elseif (imm_ == nullptr && manual_compaction_ == nullptr && !versions_->NeedsCompaction()) { // No work to be done } else { background_compaction_scheduled_ = true; env_->Schedule(&DBImpl::BGWork, this); } }
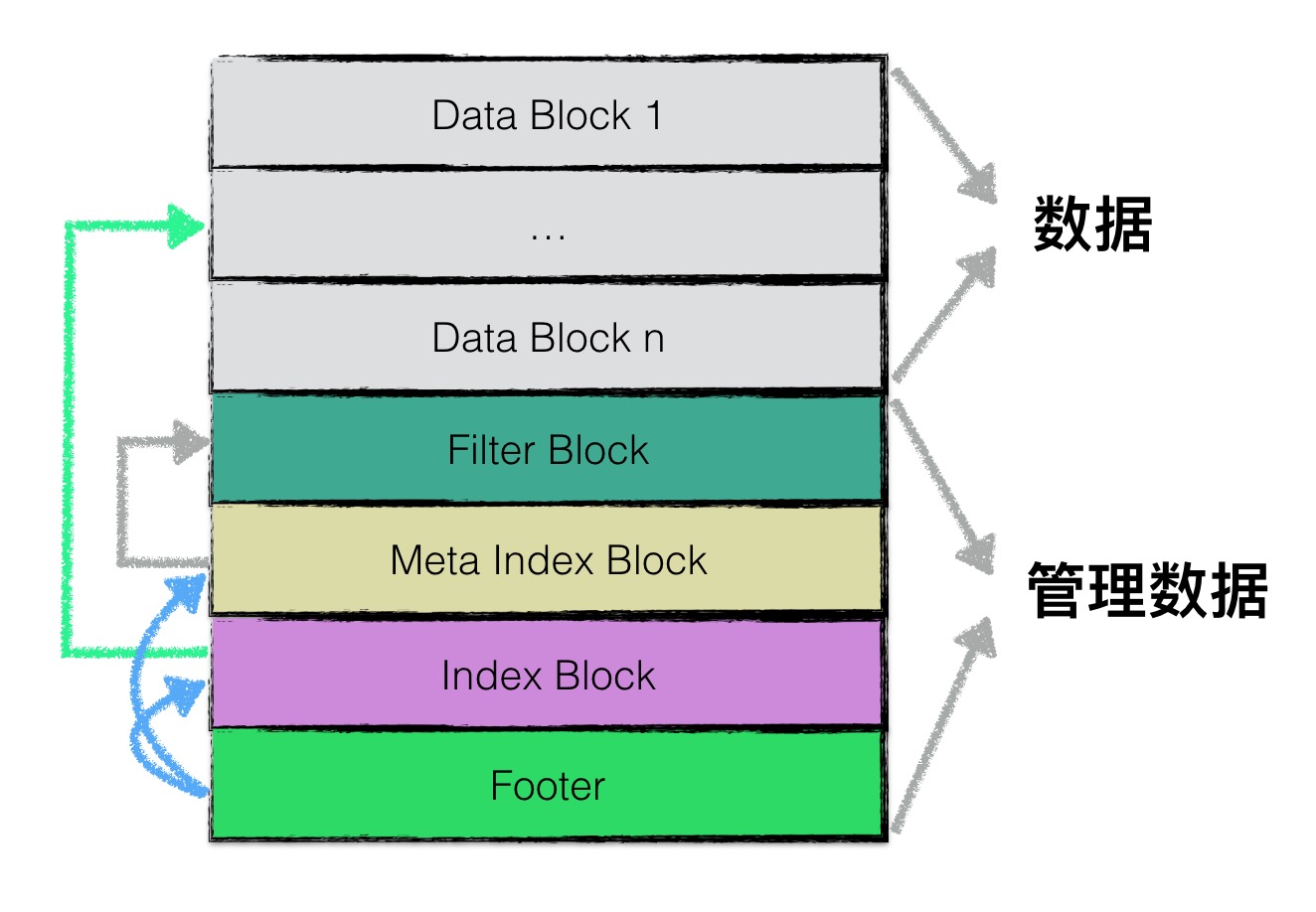
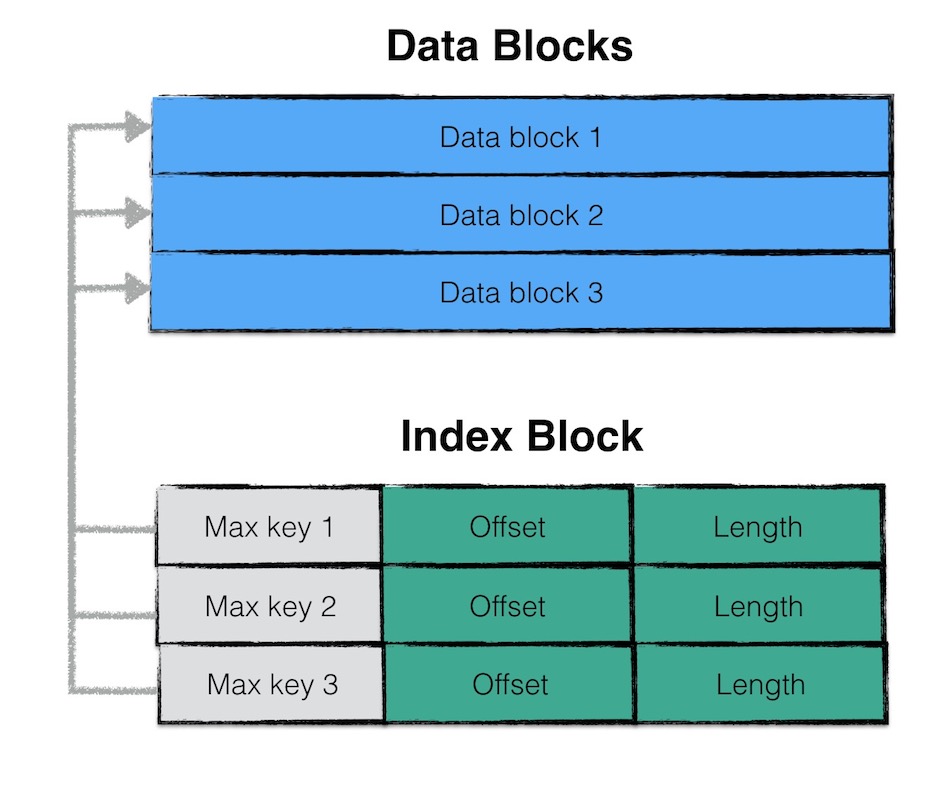
structFileMetaData { int refs; int allowed_seeks; // Seeks allowed until compaction uint64_t number; uint64_t file_size; // File size in bytes InternalKey smallest; // Smallest internal key served by table InternalKey largest; // Largest internal key served by table
Status Writer::AddRecord(const Slice& slice){ constchar* ptr = slice.data(); size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice // is empty, we still want to iterate once to emit a single // zero-length record Status s; bool begin = true; do { constint leftover = kBlockSize - block_offset_; assert(leftover >= 0); if (leftover < kHeaderSize) { // Switch to a new block if (leftover > 0) { // Fill the trailer (literal below relies on kHeaderSize being 7) assert(kHeaderSize == 7); dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover)); } block_offset_ = 0; }
// Invariant: we never leave < kHeaderSize bytes in a block. assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
RecordType type; constbool end = (left == fragment_length); if (begin && end) { type = kFullType; } elseif (begin) { type = kFirstType; } elseif (end) { type = kLastType; } else { type = kMiddleType; }
s = EmitPhysicalRecord(type, ptr, fragment_length); ptr += fragment_length; left -= fragment_length; begin = false; } while (s.ok() && left > 0); return s; }
这里唯一要注意的就是剩余空间不足时的处理方式,前面已经提过了。
在EmitPhysicalRecord中则会将发生的更改flush到磁盘上。
log_reader.h
log_reader.h中主要定义了Reader,用于读取 Log。
和Writer相对应,Reader的主要方法就是一个ReadRecord。
ReadRecord的逻辑也很简单:
使用ReadPhysicalRecord读取record,这个过程会做CRC校验
根据Type选择处理方式
LevelDB 的 Compaction
LSM 中,数据合并的过程叫做Compaction,其中有三种:
Minor Compaction: 内存中的树与磁盘文件合并
Major Compaction: SSTable 与上层 SSTable 文件合并
Full Compaction: 全部合并
LevelDB 实现了Minor Compaction和Major Compaction。
我们在前面有提到MaybeScheduleCompaction这个函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
voidDBImpl::MaybeScheduleCompaction(){ mutex_.AssertHeld(); if (background_compaction_scheduled_) { // Already scheduled } elseif (shutting_down_.load(std::memory_order_acquire)) { // DB is being deleted; no more background compactions } elseif (!bg_error_.ok()) { // Already got an error; no more changes } elseif (imm_ == nullptr && manual_compaction_ == nullptr && !versions_->NeedsCompaction()) { // No work to be done } else { background_compaction_scheduled_ = true; env_->Schedule(&DBImpl::BGWork, this); } }
voidDBImpl::BackgroundCall(){ MutexLock l(&mutex_); assert(background_compaction_scheduled_); if (shutting_down_.load(std::memory_order_acquire)) { // No more background work when shutting down. } elseif (!bg_error_.ok()) { // No more background work after a background error. } else { BackgroundCompaction(); }
background_compaction_scheduled_ = false;
// Previous compaction may have produced too many files in a level, // so reschedule another compaction if needed. MaybeScheduleCompaction(); background_work_finished_signal_.SignalAll(); }